The Importance of Wicipedia to NLP
Last year I started a research project collaborating with Irena Spasic, Padraig Corcoran, Dawn Knight and Laura Arman, training word embeddings for the Welsh language. This is a model (a mapping from words to vectors) that are useful in a number of downstream natural language processing (NLP) applications such as machine translation, sentiment analysis, entity recognition, and dependency parsing. I presented parts of this research this week at the Wales Academic Symposium on Language Technologies. The experience of working on the project has given me an appreciation of the importance of Wicipedia (the Welsh version of Wikipedia) to Welsh NLP models and language technologies.
The Welsh language suffers from primitive language models and technologies in comparison to larger languages. This makes using the Welsh language more difficult. There’s an example of this on Wikipedia itself - the search tool on the English version can recognise mis-spellings, morphologies, and variations in the form of the article title; while on the Welsh version we have to type the title exactly, including mutations and accents, because these language models aren’t available or aren’t used in Welsh. Despite this there is good news. It was great at the Symposium to hear about a load of new NLP projects such as text-to-speech and part of speech recognition tools.
Any machine learning model is only as good as the data it is trained on. For NLP the data is a corpus, which is a collection of words in context, that is a big bunch of sentences. It was interesting to hear in the Symposium that collecting a large enough Welsh corpus to train NLP models and other language technologies is a challenge across the field. For low resource languages, such as Welsh and Basque, one of the biggest sources in terms of size, the most accessible, the most varied, and the most obvious, is Wicipedia. Also, Wicipedia is the corpus source that anyone can contribute to and improve.
Wicipedia only exists thanks to amazing volunteers that work hard contributing to and maintaining it. When I realised this, I decided that I could give back to Wicipedia, and started contributing to it. From November 2019 to now I have added 124 articles (below), mainly by translating and adapting English articles. I was concentrating on two important aspects: increasing the number of words in the project, and increasing the variety of articles in the project.
-
Number of words: Increasing the amount of sentences on Wicipedia contributes directly to the quality of NLP models. Wicipedia’s size also influences how others see the language, and prehaps also at the readiness of researchers to attempt to develop models in the language.
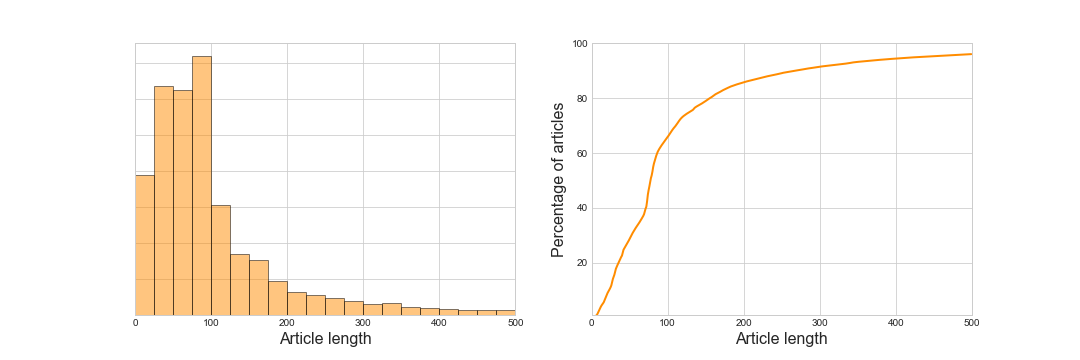
There number of stubs (very very short articles, hardly a sentence1) on Welsh Wicipedia is massive, and increasing all the time. The graph below shows the distribution of numbers of words in Wicipedia articles (data from 17-10-2020, around 132 thousand articles). Half the articles have just 77 words or less, and 62% of articles have 90 words or less. That is, 62% of Wicipedia articles have less words than this paragraph, and less than 0.7% are longer than this blog. Therefore I’m trying to add articles with plenty of content.
-
Variety: A corpus’s diversity is important for NLP. Language technolodies trained on a specialist corpus are only going to be useful in applications in that specialised context. Language technologies trained on a diverse enough corpus will have uses in a variety of applications. Furthermore, more and more multi-lingual NLP models are being developed, which can make use of resources and huge corpera in one language to improve models and applications in another minority or low resource language. These models may improve if the two corpera, although different sizes, are comparable, that is they are about the same topics. Having Wicipedia articles on a wide range of topics, prehaps with an international or generalised nature, can help.
Also, minority language Wikipedias fulfil the function of representation,2 they reflect and represent the culture and interests of that language’s speakers on an international stage. In order to ensure that Wicipedia, and the language technologies trained upon it, represent my interests and attitudes3, I need to be part of its development. Contributing your voice to a corpus that is used to study and develop language technologies mean that your are legitimising your voice. It confirms the improtance of your interests, words, terminology, and language use, and ensures that these are represented in language developments and technologies. Therefore I’m trying to add articles from a wide range of my interests.
I’ve summarised my thoughts on this in the causal loop diagram below, black arrows mean that an increase in one end causes and increase at the other, while a red arrow means that an increase in one end causes an reduction in the other. This is my opinion only:
Here’s the 124 articles I’ve contributed to Wicipedia in the year since November 2019, in the order I created them, and of course other users have edited, corrected and improved them:
- Hock
- Loretta Lynn
- Neverwhere (novel)
- Oatman, Arizona
- Community (TV series)
- Emma of Normandy
- Charter of the Forest
- Graph colouring
- One red paper clip
- Diners, Drive-Ins and Dives
- Simpson's paradox
- Herrenhausen Palace
- Los Angeles Dodgers
- Edwardian Baroque architecture
- Tonkatsu
- Coastline paradox
- Clam chowder
- Conway's Game of Life
- Only Connect
- We Didn't Start the Fire
- Wedding of Princess Elizabeth and Philip Mountbatten
- Gabriel's Horn
- HMY Britannia
- Prisoner's dilemma
- Ufology
- Bean machine
- Coin problem
- Little's law
- Griffith Park
- Streisand effect
- Scuba diving
- Bitterballen
- Googie architecture
- Pad Thai
- Sherry
- SS Great Britain
- Minimum spanning tree
- Hamiltonian path
- Star-Spangled Banner (flag)
- Kirsty MacColl
- Cobra effect
- Parks and Recreation
- Banff, Alberta
- Lanchester's laws
- Eulerian path
- Vasari Corridor
- Art Deco architecture
- Toad in the hole
- Connected component
- University of Twente
- Micronation
- Hydra effect
- Moana
- Downs-Thomson paradox
- Cities: Skylines
- Phantom time hypothesis
- Dwight Yoakam
- Santa Monica, California
- Thatcher effect
- St Edward's Crown
- Francisco de Zurbarán
- Law of large numbers
- Banana bread
- Van Honsebrouck Brewery
- Synesthesia
- Six (musical)
- Jonas Jonasson
- Yarn bombing
- Herd immunity
- Manhattanhenge
- Matanzas
- Beef Stroganoff
- The Queen's Beasts
- Judoon
- Petersen House
- Pigeonhole principle
- Cracking the Cryptic
- Texas sharpshooter fallacy
- Flag of New Mexico
- Cauchy-Riemann equations
- Koppelpoort
- Bell number
- Bachata (music)
- Matching (graph theory)
- Grauman's Chinese Theatre
- El Escorial
- Chicago Tylenol murders
- Nintendo Switch
- Paella
- Survivorship bias
- Variance
- Fields Medal
- The Louvin Brothers
- Priest hole
- Languages of Spain
- Law of truly large numbers
- Hallgrímskirkja
- Anscombe's quartet
- Matrix
- Lil Nas X
- Carlos, Prince of Asturias
- Little Shop of Horrors (musical)
- Mann–Whitney U test
- Town Musicians of Bremen
- De Morgan's laws
- Neo-Andean architecture
- New Mexico History Museum
- Shibboleth
- Mean value theorem
- Integration by parts
- Caesar cipher
- John Mulaney
- Pioneer plaques
- k-means clustering
- Planet Zoo
- Aladdin (2019 film)
- Sceptre
- Coronation Chair
- Causal loop diagram
- Fileteado
- Bhaji
- Independence (probability theory)
- Dijkstra's algorithm
- Close encounter
-
there’s a number of claims that the number of Wikipedia articles in some language contributes directly towards funding that language (example, example), though I can’t find evidence of this. However, these stubs do skew being able to interpret the statistic ‘number of articles’ as a measure of the size of Wicipedia. ↩
-
see this article for an example. ↩
-
in my opinion Welsh Wicipedia has an ‘identity politics’ bias - again, only by contributing to the project can my attitudes be represented. ↩